¿Que es el machine learning?
El Machine Learning es una disciplina del campo de la Inteligencia Artificial que, a través de algoritmos,
dota a
los ordenadores de la capacidad de identificar patrones en datos masivos y elaborar predicciones (análisis
predictivo). Este aprendizaje permite a los computadores realizar tareas específicas de forma autónoma, es
decir,
sin necesidad de ser programados.
El término se utilizó por primera vez en 1959. Sin embargo, ha ganado relevancia en los últimos años debido al
aumento de la capacidad de computación y al boom de los datos. Las técnicas de aprendizaje automático son, de
hecho, una parte fundamental del Big Data.
Hay difernetes tipos
de implementacion que pueden clasificarse en 3 categorias
- Aprendizaje supervisado
- Aprendizaje no supervisado
- Aprendizaje de refuerzo según la naturaleza de los datos que recibe.
Aprendizaje supervisado
En el aprendizaje supervisado, los algoritmos trabajan con datos “etiquetados” (labeled data), intentado
encontrar una función que, dadas las variables de entrada (input data), les asigne la etiqueta de salida
adecuada.
El aprendizaje supervisado se suele usar en:
- Problemas de clasificación (identificación de dígitos, diagnósticos, o detección de fraude de identidad).
- Problemas de regresión (predicciones meteorológicas, de expectativa de vida, de crecimiento etc).
Los algoritmos más habituales que aplican para el aprendizaje supervisado son:
- Árboles de decisión.
- Clasificación de Naïve Bayes.
- Regresión por mínimos cuadrados.
- Regresión Logística.
- Support Vector Machines (SVM).
- Métodos “Ensemble” (Conjuntos de clasificadores).

Aprendizaje no Supervisado
El aprendizaje no supervisado tiene lugar cuando no se dispone de datos “etiquetados” para el entrenamiento.
Sólo conocemos los datos de entrada, pero no existen datos de salida que correspondan a un determinado input.
Árbol de decisión en Machine Learning
Los algoritmos de aprendizaje basados en árboles se consideran uno de los mejores y más utilizados métodos de
aprendizaje supervisado. Los métodos basados en árboles potencian los modelos predictivos con alta precisión,
estabilidad y facilidad de interpretación.
A diferencia de los modelos lineales, mapean bastante bien las relaciones no lineales. Son adaptables para
resolver cualquier tipo de problema (clasificación o regresión).
Métodos como árboles de decisión, bosque aleatorio, aumento de gradiente se utilizan popularmente en todo tipo de
problemas de ciencia de datos. Por lo tanto, para cada analista (más reciente también), es importante aprender
estos algoritmos y usarlos para modelar.
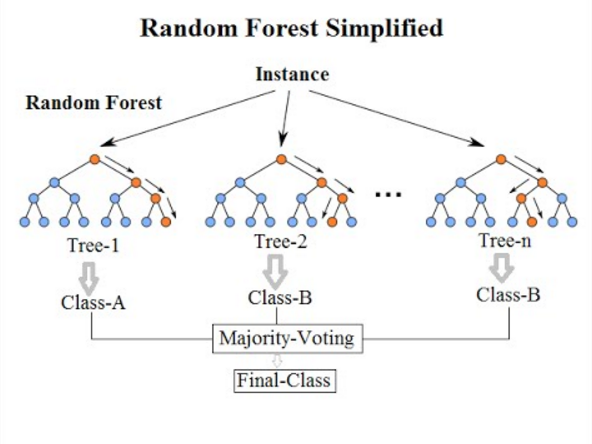
Bosque aleatorio
Los Bosques Aleatorios es un algoritmo de Machine Learning flexible y fácil de usar que produce, incluso sin
ajuste de parámetros, un gran resultado la mayor parte del tiempo. También es uno de los algoritmos más
utilizados, debido a su simplicidad y al hecho de que se puede usar tanto para tareas de clasificación como de
regresión.
Los Bosques Aleatorios es un algoritmo de aprendizaje supervisado que, como ya se puede ver en su nombre, crea
un bosque y lo hace de alguna manera aleatorio. Para decirlo en palabras simples: el Bosque Aleatorio crea
múltiples árboles de decisión y los combina para obtener una predicción más precisa y estable. En general,
mientras más árboles en el bosque se vea, más robusto es el bosque.
En este algoritmo se agrega aleatoriedad adicional al modelo, mientras crece los árboles, en lugar de buscar
la característica más importante al dividir un nodo, busca la mejor característica entre un subconjunto
aleatorio de características. Esto da como resultado una amplia diversidad que generalmente resulta en un
mejor modelo.
Redes neuronales
Básicamente consisten en redes de neuronas simuladas conectadas entre sí. Existen varios tipos en función de su
arquitectura y forma de aprendizaje. Una de las más utilizadas es la red basada en varias capas de neuronas de
tipo perceptrón, entrenadas mediante la técnica de retropropagación (backpropagation).
Las redes neuronales permiten extraer información útil y producir inferencias a partir de los datos disponibles
gracias a su capacidad de aprendizaje. Sus propiedades como reconocedores de patrones altamente tolerantes a
errores permiten combinar las cualidades del razonamiento humano con la lógica precisa y la memoria de los
ordenadores, por lo que resultan de gran utilidad en medicina como sistemas de apoyo a las decisiones clínicas.